9 minutes
In-process Sandboxing with Memory Protection Keys
By Ayrton Muñoz & Stephen CraneModern software applications contain many distinct smaller components, such as libraries or plugins, that are often written by third-parties. Developers typically don’t have the resources to exhaustively review and scrutinize third-party source code, leaving application integrators and operational teams with little visibility into the security and correctness of this code. These libraries provide specialized functionality, and often do not need access to the entire application, but the status quo is that an application is an amalgamation of all this code into one process with all components having equal access to all data in the application.
Combining distinct components into a single process is convenient and saves implementation time, but this architecture conflicts with the security idea of least privilege - each component should only have the privileges and access required for its job. By placing multiple components in a single process, one component can affect another - even if they’re logically unrelated. One alternative architecture, implemented in modern web browsers like Chrome and Firefox, is separating risky components into their own processes with fewer privileges which effectively sandboxes these components. This is typically most relevant to components that process input data from potentially untrusted sources, such as media codecs and parsers. However, retrofitting this architecture onto an existing application can be costly and time consuming.
In this post we’ll introduce our alternative in-process sandboxing runtime and show how to retrofit it onto existing codebases with lower developer effort and runtime overhead than creating separate processes. Our sandbox is currently intended for C programs running on x86-64, but we have also previously prototyped support for Rust and are working on an ARM64 port. We’ll also describe how it could benefit other codebases using C/C++ libraries by preventing the lack of memory-safety from being abused to break invariants enforced by higher-level languages.
Sandboxing with Processes
Sandboxing with processes works by placing components into separate executables that run in different address spaces. This isolates each component’s memory and significantly increases the barrier for an attacker to arbitrarily access another component’s data. Essentially, when multiple components coexist in a single address space, a missing bounds check on a pointer dereference in one component can affect another, logically unrelated component. While this spatial memory-safety problem has been solved by modern languages that automatically insert bounds checks, it is a fundamental issue for C/C++. Due to the large ecosystem of libraries written in C/C++ and the niche they occupy among languages, improving memory-safety remains an important challenge. This would also be beneficial for codebases in managed languages, such as Java, that rely on C/C++ libraries (e.g. for performance-critical operations) since the lack of memory-safety can be abused to break guarantees which the higher-level language tries to provide. This could be things like type-system invariants enforced by a higher-level language. Essentially memory-safety matters because those bugs undermine guarantees that developers rely on to reason about a program.
With components in separate address spaces, the barrier for attackers is increased because they can only interact with assistance from the operating system (OS). This means an attacker would need more than a missing bounds check in a component that processes untrusted inputs. An attacker would also need to leverage vulnerabilities in the OS or abuse the interface between processes to freely access the privileged component’s memory. Due to the cost of factoring an application into processes, developers typically design the process interfaces very carefully so they can’t be misused. However processes execute independently, so this refactoring involves making the individual components asynchronous. It’s also not always practical to increase the number of processes because each additional process imposes memory and management overhead imposed on the operating system.
In contrast, in-process sandboxing uses a single address space leading to lower memory requirements. It also avoids the need to refactor components around an asynchronous inter-process communication (IPC) protocol which can take significant developer effort. In our runtime we also delineate the sandbox along existing boundaries making it easier to reason about interactions between components. It also does not preclude the use of multiple processes and can be used as a more fine-grained sandbox on top of the coarse protection provided by multiple processes.
Memory Protection Keys
The granularity of in-process sandboxing depends on the hardware primitives used to isolate memory. Our approach is to use x86-64’s Memory Protection Keys (MPK) feature which has been available since 2016 and is now readily available on common cloud computing infrastructure such as Amazon’s EC2 C5 instances. It provides 16 “protection keys” (pkeys) for each process which we use to define sandbox compartments. A pkey is a tag assigned to every memory page in a process and is compared against a dedicated register before each read or write to check if the page may be accessed. Our runtime assigns libraries different pkeys and changes this Protection-Key Rights Register (PKRU) each time the program jumps between libraries. Pkeys alone are not a security feature so our runtime combines it with x86-64’s Control-flow Enforcement Technology (CET) feature to ensure that the PKRU only changes at transitions between libraries. This ensures that each library component cannot access memory tagged with another pkey.
Developer Workflow
Sandboxing improves memory-safety, but it also introduces cognitive overhead for developers who then have to consider new interactions between sandbox compartments. Essentially, sandboxing provides minimal benefit if the interface defined at compartment boundaries allows arbitrary (and potentially sensitive) data to pass through. To mitigate this, we chose to delineate the sandbox compartments using pre-existing boundaries. We define a compartment as a set of libraries which is assigned a unique pkey and use the library APIs as the compartment interfaces. More specifically this applies to any dynamic shared object (DSO), so it includes any shared libraries (i.e. .so or .dll files) as well as the main program executable itself. This means that the existing library APIs become the interface between sandbox compartments. The benefits of this choice are very specific to the library’s API (e.g. a library with a void write_to_arbitrary_address(int *addr, int val) API would not benefit much) , but it should make it simpler to evaluate an interface’s suitability as a sandbox boundary.
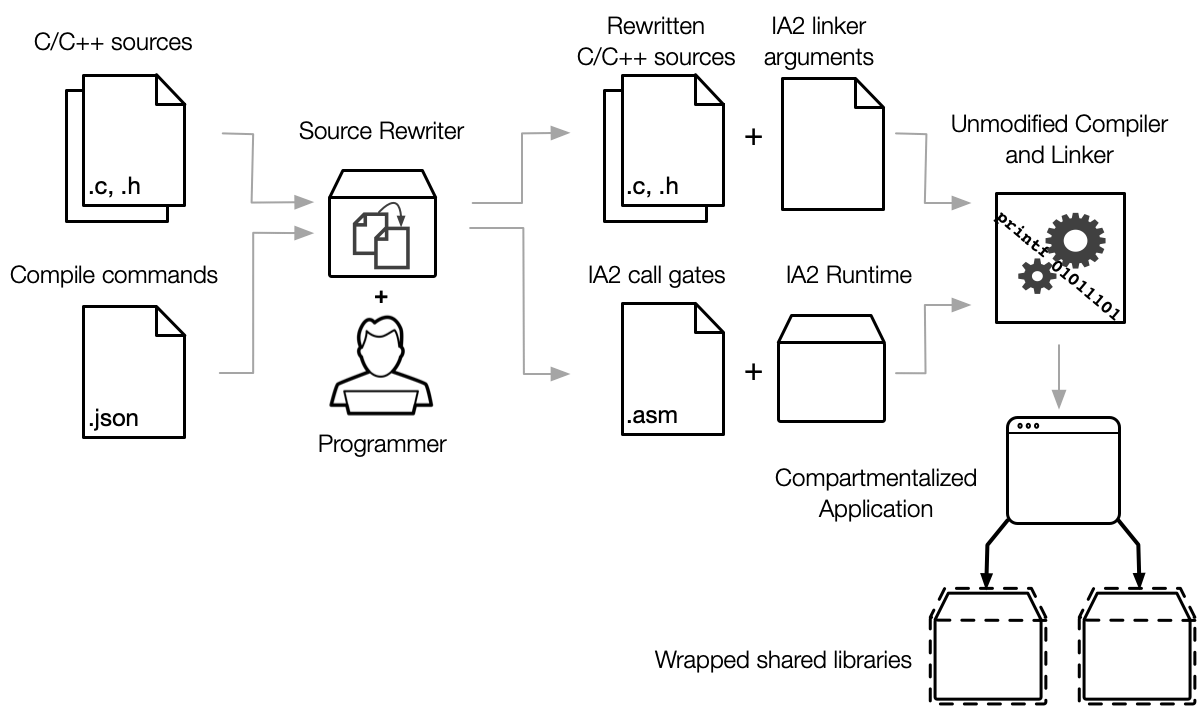
Our runtime tries to be as transparent as possible to developers, but libraries at compartment boundaries require source code annotations, mainly with information about control-flow. To simplify the sandboxing process, we developed a source rewriter tool which takes in C source files and adds the annotations wherever they can be inferred. Instead of annotating source files in-place, the rewriter creates copies in an output directory which are then passed onto the existing build system. This minimizes the amount of developer-facing annotations in sandboxed codebases. Ideally the only annotations developers should encounter while working are those that cannot be reasonably inferred such as annotations for what variables must be shared between compartments. The rewriter also generates a new source file defining call gates for transitions between compartments and a file of extra linker arguments required to insert the call gates. These artifacts are then passed on to a standard compiler as shown below to create the sandboxed application. While we currently support GCC and Clang, our runtime intends to be toolchain-agnostic so we may add support for other compilers as the need arises.
Threat Model
As we alluded to earlier, the benefits of sandboxing depend on what is allowed to cross compartment boundaries. Of the 16 MPK protection keys, one default key is accessible regardless of the PKRU so our sandbox supports up to 15 compartments. Each compartment consists of a set of DSOs and by default any memory they handle is not accessible from outside the compartment. This includes variables on the stack, in the heap, global and static variables and thread-local storage. Compartments can also contain prebuilt libraries, assuming the prebuilts are not at the compartment boundary (i.e. they don’t directly interact with DSOs in other compartments). Also our threat model assumes that compartments are mutually distrusting. Even if only one compartment contains sensitive user data, by only allowing each compartment to access its own data we ensure that libraries can only interact in ways explicitly allowed by the APIs. We chose this model as it is reasonably generic and can be specialized to fit the needs of different applications. Other use-cases we considered include sandboxing multiple, potentially untrusted 3rd-party libraries within a small trusted application and sandboxing a smaller enclave-style compartment within a larger application. Here “untrusted” assumes that code was not written to be intentionally malicious, but may have unknown memory-safety vulnerabilities. We also assume that a potential attacker has access to the on-disk binaries, so any data embedded in the on-disk binary is not sensitive.
Performance Costs
Like any sandboxing solution, the elements of our approach have their costs in terms of performance. On Linux the mechanism for tagging pages with pkeys is the pkey_mprotect syscall. This has the usual costs associated with a syscall which include a context-switch into the OS as well as modification of the page-table entries for the specified memory pages. This mainly happens when initializing the program or creating new threads so in steady-state it should not impose a burden. Modifying the PKRU can be done with a single wrpkru userspace instruction which introduces minimal overhead on its own. Since our runtime provides extra assurances about the confidentiality of data in each compartment (e.g. it uses a separate stack for each compartment), transitions do have a higher switching cost than a single instruction. Since transitions are entirely in userspace, they require control-flow integrity (CFI) checks to prevent a compromised compartment from abusing a wrpkru to gain access to other compartments. As mentioned above, we use CET’s shadow stack and indirect branch tracking which impose minimal overhead since the checks are done by the hardware. The PKRU is also a thread-local register so our runtime requires no additional synchronization between threads.
Conclusion
Due to the pervasiveness of C/C++ code and the breadth of their ecosystem of libraries, improving memory-safety is an important challenge. In-process sandboxing is an underutilized alternative to the common approach of separating an application into multiple processes. However, with the availability of new hardware primitives it has become a viable approach on x86-64 and our sandboxing framework provides a reasonably generic solution which can be retrofitted onto existing C codebases. If you think your software could benefit from the assurances our sandbox provides, feel free to contact us at [email protected]. We’d love to hear from you and see how our framework can be specialized to more use-cases. In a follow-up post we’ll do a more technical, hands-on walkthrough of how to sandbox an application.