8 minutes
Emitting Safer Rust with C2Rust
By Per Larsen & Eddy WestbrookIn this post, we will discuss recent results from Immunant and Galois in extending C2Rust to emit memory-safe Rust in certain cases. With this work we aim to shift a meaningful part of the translation burden from the human to the machine. Up until now, C2Rust has only been able to translate C to unsafe Rust that is no safer than the original input C code. Although this provides a starting point for manual refactoring into idiomatic and safe Rust, this work had to be done by the human. By using a combination of static and dynamic analysis, the current in-development version of C2Rust can now perform some of the lifting to safe Rust automatically. This post describes how this analysis works and how we are using it to make it easier to translate unsafe C programs into memory-safe Rust.
Rust is definitely a batteries-included language, but suppose for the sake of exposition that it did not include the ability to sort an array of integers. Further, imagine that we decided to address this shortcoming by migrating an existing C implementation such as the one below:
void insertion_sort(int const n, int * const p) {
for (int i = 1; i < n; i++) {
int const tmp = p[i];
int j = i;
while (j > 0 && p[j-1] > tmp) {
p[j] = p[j-1];
j--;
}
p[j] = tmp;
}
}
If we feed this to C2Rust (try it yourself on c2rust.com), we get this Rust out the other end:
pub unsafe extern "C" fn insertion_sort(
n: libc::c_int, p: *mut libc::c_int) {
let mut i: libc::c_int = 1 as libc::c_int;
while i < n {
let tmp: libc::c_int = *p.offset(i as isize);
let mut j: libc::c_int = i;
while j > 0 as libc::c_int &&
*p.offset((j - 1 as libc::c_int) as isize) > tmp {
*p.offset(j as isize) =
*p.offset((j - 1 as libc::c_int) as isize);
j -= 1
}
*p.offset(j as isize) = tmp;
i += 1
};
}
This code could be rewritten to use fewer casts, but that’s a topic for another post; our goal here is to reduce unsafety by avoiding the use of raw pointers since they permit out of bounds accesses. If we change insertion_sort’s second formal parameter p, we’ll have to change the actual argument passed to insertion_sort at all call sites. Say we have a call in main:
unsafe fn main_0() -> libc::c_int {
let mut arr1: [libc::c_int; 3] = [1, 3, 2];
insertion_sort(
3 as libc::c_int, arr1.as_mut_ptr());
// …
}
We need to understand how the pointer to arr1 flows from main_0 to insertion_sort. This is trivial in our simple example, but in the general case, no algorithm exists that always gives the correct answer to aliasing questions such as “can a pointer X be used to access allocation Y”? The problem, in a nutshell, is that most programs are sufficiently complex that we cannot analyze all the states they could possibly be in. We can build analyses that reason over all possible program states (also known as static program analyses) but they often fall back to conservatively correct answers such as “maybe” where a definite “yes/no” answer is required. For this reason, and to facilitate experimentation, we augment what we can learn from relatively simple types of static analysis with dynamic observations collected during program execution. Fuzz testing tools similarly eschew complicated static analyses and opt instead to detect access violations at runtime by feeding a large number of random inputs to programs. Our thinking is that we can similarly learn enough about how programs use pointers to discover how to express the same computation in the Rust type system. This won’t work all of the time, but that’s okay as long as it works sufficiently often to save programmers a meaningful amount of time. Just like a fuzzer, we instrument the generated Rust code and run it on some example inputs. We use the information we generate to build a pointer derivation graph or PDG.
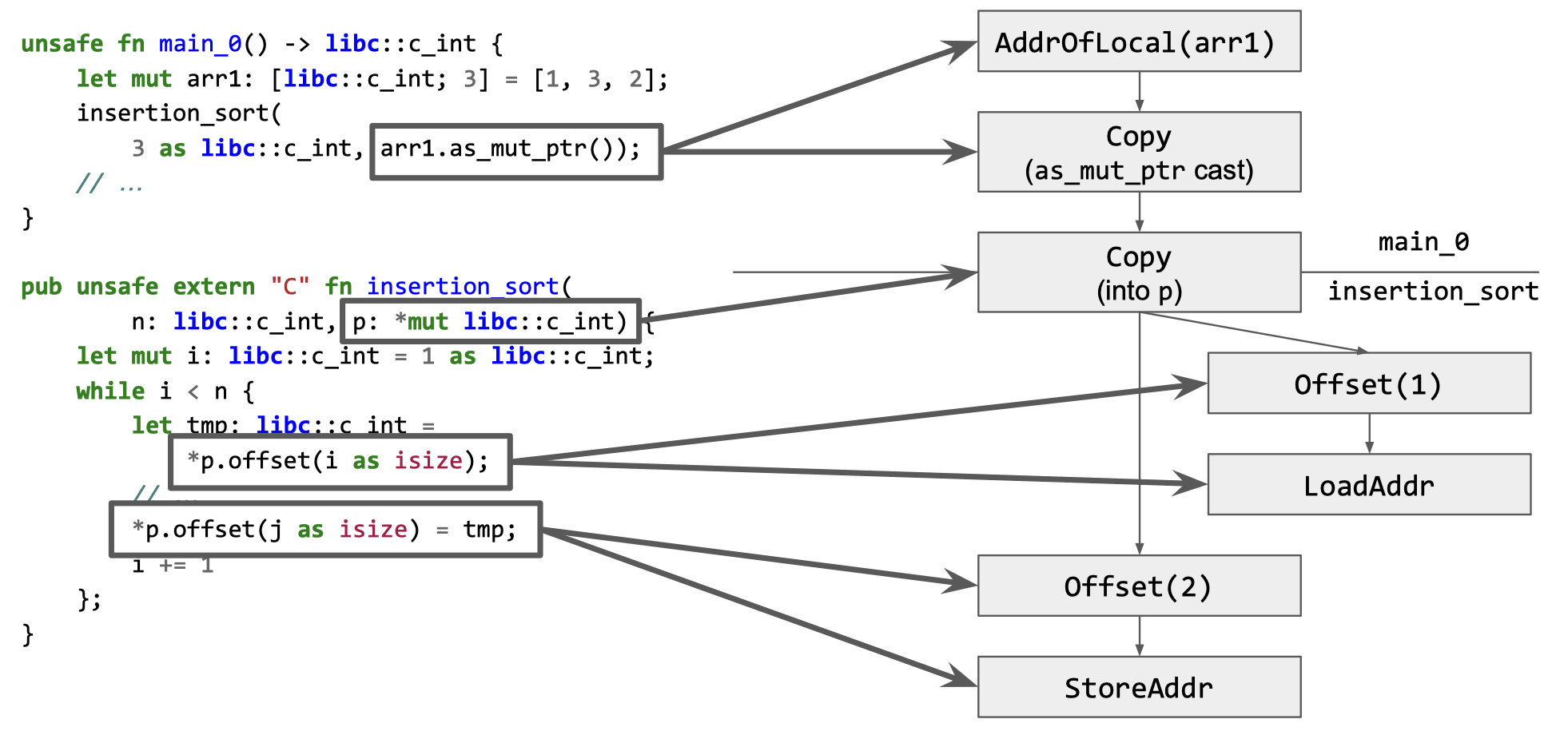
The pointer derivation graph is a summary of observations that we’ll use to transform our program. (If we had a static analysis available that gave us the same information, we could have used that; alas, interprocedural points-to analysis is a dragon we’d rather not slay.) Now that we have a PDG for the pointer argument p, we can compute what permissions are needed at each point in the program where p is defined and used. The five permissions we care about are
- WRITE: when the program writes to the pointee
- UNIQUE: when the pointer is the only way to access a given memory location
- FREE: when the pointer will eventually be passed to free1
- OFFSET_ADD: when we’ll add an offset to the pointer, e.g. to access an array element
- OFFSET_SUB: when we may subtract an offset from the pointer
The permissions needed by a pointer map to Rust types according to the following (non-exhaustive2) table:
| Write | Unique | Free | Offset | Resulting ptr type |
|---|---|---|---|---|
| &T | ||||
| x | x | &mut T | ||
| x | &Cell3 | |||
| x | x | Box | ||
| x | &[T] | |||
| x | x | x | &mut [T] | |
| x | x | x | Box<[T]> |
Let’s use this table and the PDG to rewrite the array of integers to insertion sort:
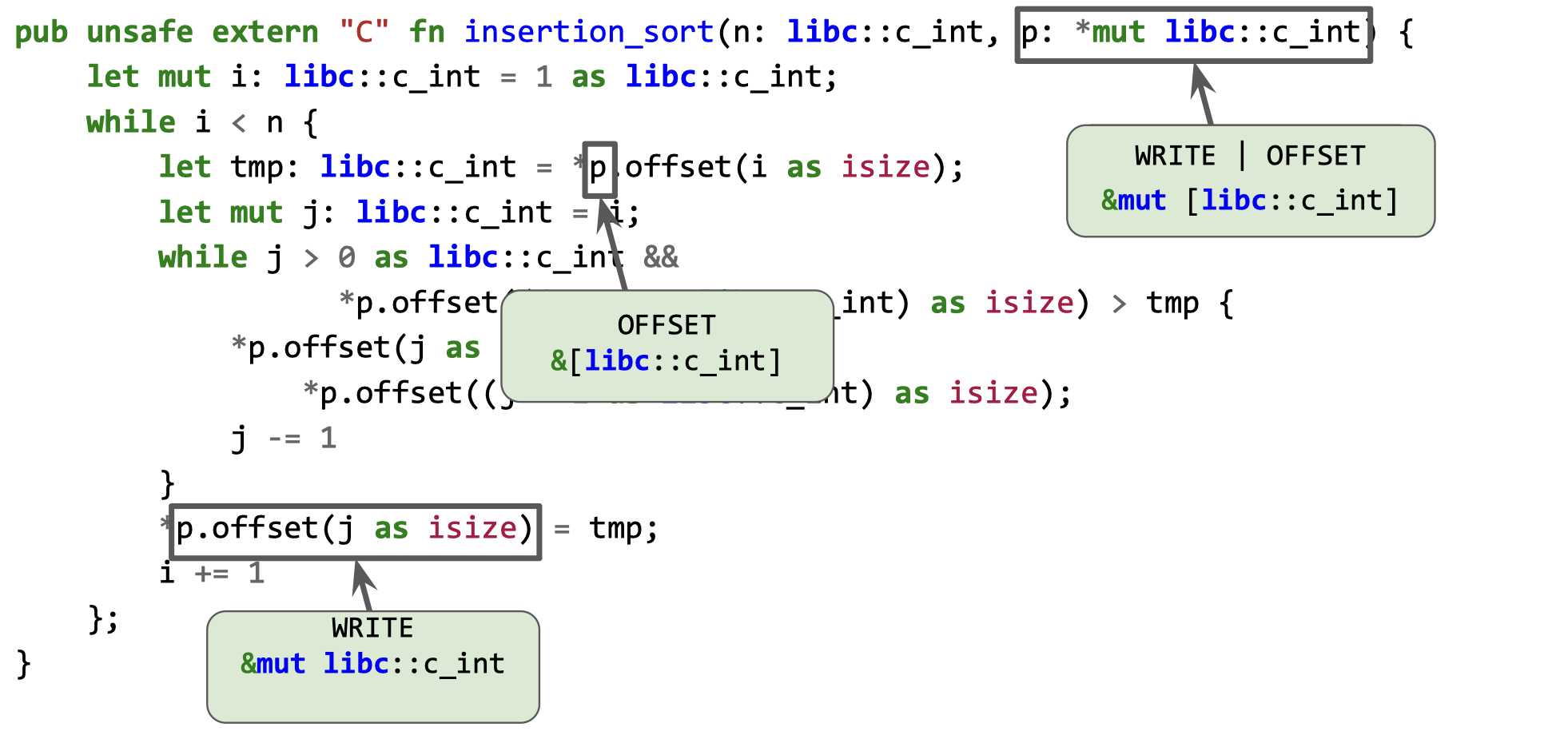
The parameter p needs the OFFSET4 permission because it is used as the base pointer in array indexing operations and the WRITE permission because one of these operations is a store. The last row permissions table gives us the safe type for data needing WRITE and OFFSET operations, which is &mut [T], meaning that &mut [libc::c_int] is the appropriate concrete type for p. Once we update the type of the formal parameter p, we can propagate the change throughout the function body. We replace all uses of offset with proper array indexing operations, which in turn requires us to cast the index to a usize instead of a isize. We are not yet able to mechanically perform these rewriting operations but once we get there, the result should look like this:
pub fn insertion_sort(n: libc::c_int, p: &mut [libc::c_int]) {
let mut i: libc::c_int = 1 as libc::c_int;
while i < n {
let tmp: libc::c_int = p[i as usize];
let mut j: libc::c_int = i;
while j > 0 as libc::c_int &&
p[(j - 1 as libc::c_int) as usize] > tmp {
p[j as usize] =
p[(j - 1 as libc::c_int) as usize];
j -= 1
}
p[j as usize] = tmp;
i += 1
}
}
unsafe fn main_0() -> libc::c_int {
let mut arr1: [libc::c_int; 3] = [1, 3, 2];
insertion_sort(3 as libc::c_int, &mut arr1); // propagate type change to
// caller
// …
}
At the time of writing, we are implementing the ability to apply rewrites automatically. We are using (fragments of) the lighttpd web server as a model organism. While all code is available on the C2Rust GitHub repository, much work remains before we have a version that is suitable for anything beyond internal dogfooding. Expect a follow-up blog post covering how to try out lifting to safer Rust on your own code sometime in the second half of 2023.
The million-dollar question is how close to idiomatic Rust code we can get with the current approach. As previously mentioned, the limits of static analysis are well known. We don’t have the resources to build the best possible static analysis, so we very quickly run up against the practical limits of what we can do in a fully automatic and correctness-preserving manner. (We use a liberal notion of correctness which allows us to convert a well-defined C program into Rust that panics, this will allow us to add bounds checking and use RefCell among other things). The results obtained via dynamic analysis can be used as an oracle to speculate on properties that are not available via static analysis. Whenever possible, we will perform speculative rewrites such that the code will panic in case of misspeculation. Programmer can remove asserts inserted to guard against misspeculation to confirm that a property will always hold. This too will be covered in a future post. In the meanwhile, you can always reach us in the C2Rust discord channel and on the GitHub repository. We look forward to hearing from you!
This research was developed with funding from the Defense Advanced Research Projects Agency (DARPA). The views, opinions and/or findings expressed are those of the author and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government.
Distribution Statement “A” (Approved for Public Release, Distribution Unlimited)
-
In program analysis, we say a node in the program is post-dominated by (i.e, will eventually reach) a node that frees the pointer. ↩︎
-
We have yet to determine the remaining mappings. For instance, we must rule out some otherwise plausible options like
&[RefCell<T>]for mutable, shared pointers if we need to preserve the memory layout. ↩︎ -
Currently we only support
Cell(partially), but we may eventually pick eitherCellorRefCell↩︎ -
The OFFSET permission is equivalent to OFFSET_ADD | OFFSET_SUB. Our example ignores the distinction but in practice, we’d need to prove that p.offset is only called with positive values (OFFSET_ADD) to perform the rewrites shown in this post. If our dynamic analysis only observes calls to p.offset with positive offsets, we can speculate that offsets are always positive as long we rewrite the code such that the program panic’s in case of misspeculation. ↩︎